第三财经网 2025-04-06 06:20 688
我们对人工智能了解多少?
对于 OpenAI、Google 和 Meta 等公司在过去一年发布的大型语言模型,答案是:基本上什么都没有。
这些公司通常不会发布有关使用哪些数据来训练模型或使用哪些硬件来运行模型的信息。人工智能系统没有用户手册,没有这些系统能够执行的所有操作列表,也没有对它们进行哪些类型的安全测试。
尽管一些人工智能模型已经开源,这意味着它们的代码是免费赠送的,但公众仍然不太了解它们的创建过程,或者它们发布后会发生什么。
本周,斯坦福大学的研究人员推出了一个评分系统,他们希望该系统能够改变现状。该系统被称为基础模型透明度指数,对10个大型人工智能语言模型(有时称为“基础模型”)的透明度进行评级。
该索引中包括流行的模型,如 OpenAI 的 GPT-4(为 ChatGPT 的付费版本提供动力)、Google 的 PaLM 2(为 Bard 提供动力)和 Meta 的 LLaMA 2。还包括一些不太知名的模型,如亚马逊的 Titan Text 和 Inflection AI 的 Inflection -1,为 Pi 聊天机器人提供动力的模型。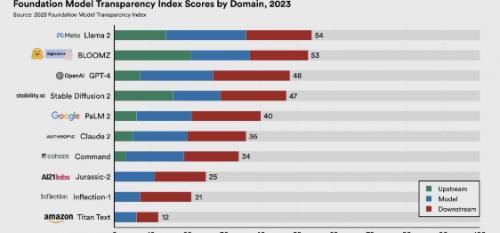 为了得出排名,研究人员根据100项标准对每个模型进行了评估,包括其制造商是否披露训练数据的来源、所使用的硬件信息、训练所涉及的劳动力以及其他细节。该排名还包括有关用于生成模型本身的劳动力和数据信息,以及研究人员所谓的“指标”,这些指标与模型发布后的使用方式有关。
为了得出排名,研究人员根据100项标准对每个模型进行了评估,包括其制造商是否披露训练数据的来源、所使用的硬件信息、训练所涉及的劳动力以及其他细节。该排名还包括有关用于生成模型本身的劳动力和数据信息,以及研究人员所谓的“指标”,这些指标与模型发布后的使用方式有关。
例如,提出一个问题:“开发者是否公开其存储、访问和共享用户数据的协议?”
研究人员称,这10个模型中透明度最高的是 LLaMA 2,得分为54%。GPT-4 的透明度得分排名第三,为40%,与 PaLM 2 相同。
斯坦福大学基础模型研究中心负责人 Percy Liang 将该项目描述为对人工智能行业透明度下降的必要回应。随着资金迅速涌入人工智能领域,科技领域最大的公司争相争夺主导地位,许多公司最近的 AI 发展趋势是保密的。

三年前,人们不断发布有关模型的更多细节。但现在,没有关于这些模型是什么、它们是如何构建以及它们在哪里使用的信息。
随着模型变得越来越强大,以及数百万人将人工智能工具融入他们的日常生活,透明度现在显得尤为重要。更多地了解这些系统的工作原理将使监管机构、研究人员和用户更好地了解他们正在处理的问题,并使他们能够更好地向模型背后的公司提出问题。
关于这些模型的构建,相关公司正在做出一些相当重要的决定,但这些决定没有被公开。
当人工智能高管被问为什么不公开分享更多有关其模型的信息时,通常会听到他们的三种常见回答。
首先是诉讼。多家人工智能公司已经被作家、艺术家和媒体公司起诉,指控他们非法使用受版权保护的作品来训练他们的人工智能模型。到目前为止,大多数诉讼都针对开源人工智能项目,或披露其模型详细信息的项目。
毕竟,如果你不知道一家公司摄取了哪些艺术品,就很难起诉它摄取了哪些艺术品。人工智能公司的律师担心,他们对模型的构建方式说得越多,他们就越会让他们自己陷入昂贵且烦人的诉讼中。
第二个常见的反应是竞争。大多数人工智能公司认为,他们的模型之所以有效,是因为他们拥有某种秘密武器,比如其他公司没有的高质量数据集、产生更好结果的微调技术以及一些优化技术。他们认为,如果你强迫人工智能公司披露这些秘诀,你就会让他们将来之不易的智慧拱手让给竞争对手,而竞争对手可以轻松复制它们。第三个回答是安全。一些人工智能专家认为,人工智能公司披露的有关其模型的信息越多,人工智能的进步就会加速得越快。因为每家公司都会看到所有竞争对手在做什么,并立即尝试通过构建更好、更大、更快的模型来超越他们。如果人工智能变得过于强大、过快,这可能会让我们所有人陷入危险。

斯坦福大学的研究人员并不相信这些解释。他们认为,人工智能公司应该被迫发布尽可能多的有关强大模型的信息,因为用户、研究人员和监管机构需要了解这些模型的工作原理、局限性以及可能更多的危险。
研究人员之一里什·博马萨尼 (Rishi Bommasani) 表示,随着这项技术的影响力不断上升,透明度却在下降。如果人工智能高管担心诉讼,也许他们应该争取合理使用豁免,以保护他们使用受版权保护的信息来训练模型的能力,而不是隐藏证据。
如果他们担心将商业秘密泄露给竞争对手,他们可以披露其他类型的信息,或通过专利保护他们的想法。如果他们担心开始一场人工智能军备竞赛……
那么,我们不是已经参与其中了吗?我们不能在黑暗中进行人工智能革命。如果我们想让人工智能改变我们的生活,我们就需要了解它的黑匣子。
热门文章







